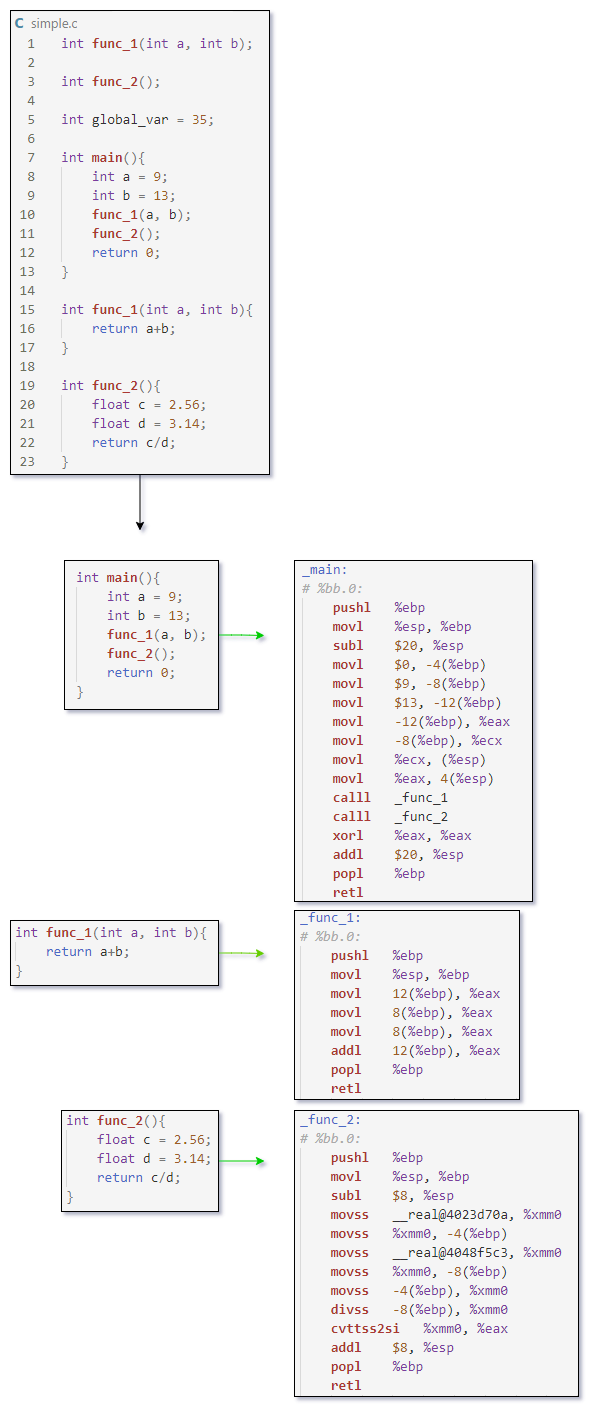
Cookies
(This section assumes that you have a basic knowledge of what Cookies are. For proper introduction and more details about cookies, please read the Mozilla Developer Docs: https://developer.mozilla.org/en-US/docs/Web/HTTP/Cookies. The flowcharts in this section are created by Nandan Desai)
Cookies are created on the client side when either the server responds with Set-Cookie header or when the cookies are set using Document.cookie in JavaScript.
And the browser sends the Cookies to the server on the next request using the Cookie header.
Understanding the intricacies of cookies boils down to understanding various cookie attributes.
Cookie attributes can be classified into two main categories:
- The attributes that restrict access to cookies (like
SecureandHttpOnly) - The attributes that define where the cookies are sent (like
SameSite,DomainandPath)
'Secure' and 'HttpOnly'
Cookies that have Secure attribute set are only sent to the server on an encrypted (HTTPS) network. Also, sites with http:// in their URL can't set Secure attribute on cookies.
Cookies that have HttpOnly attribute set are not accessible via JavaScript and are sent to the server by the browser automatically when all the proper conditions are met.
'Domain', 'Path' and 'SameSite'
- 'Domain' attribute
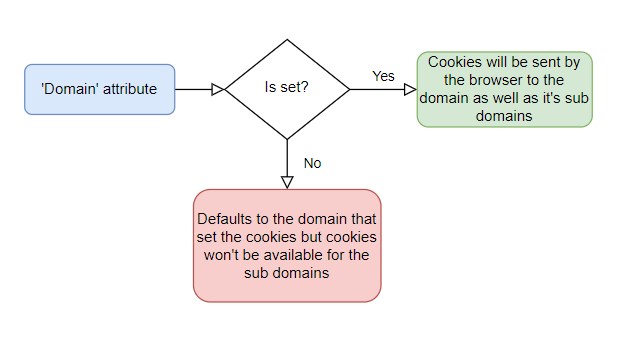
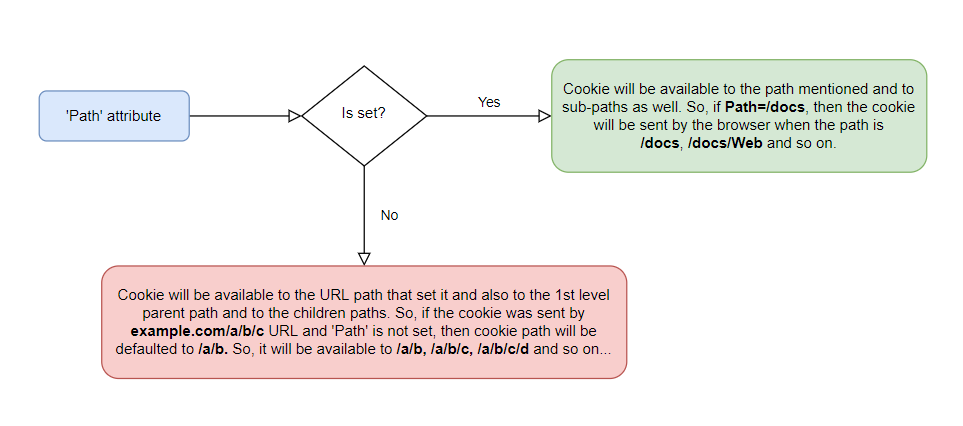
- 'Path' attribute
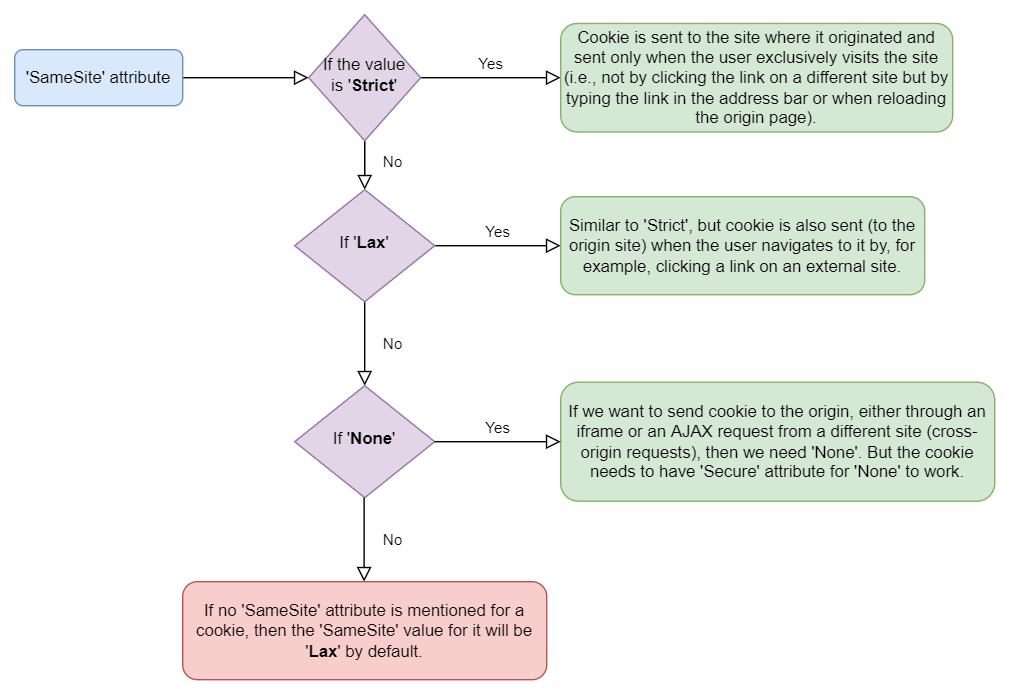
- 'SameSite' attribute
Here, the "site" refers to the domain combined with the scheme (http or https). For example, http://example.com and https://example.com are different sites according to this definition.
CORS (Cross-Origin Resource Sharing)
(Most of the CORS-related content presented here is either a direct copy-paste of Mozilla Developer Docs or I've made some minor modifications to make certain things simpler to understand. You can get more details on this topic here: https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS)
In simple words, CORS is a communication between the server and the browser about what the browser is allowed to do when it receives some content from the server. It's like the server is doing Access Control on the browser.
Suppose web content at https://foo.example wishes to invoke content on domain https://bar.other. Code of this sort might be used in JavaScript deployed on foo.example:
const xhr = new XMLHttpRequest();
const url = 'https://bar.other/resources/public-data/';
xhr.open('GET', url);
xhr.onreadystatechange = someHandler;
xhr.send();
This operation performs a simple exchange between the client and the server, using CORS headers to handle the privileges:

Let's look at what the browser will send to the server in this case:
GET /resources/public-data/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Connection: keep-alive
Origin: https://foo.example
The request header of note is Origin, which shows that the invocation is coming from https://foo.example.
Now let's see how the server responds:
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 00:23:53 GMT
Server: Apache/2
Access-Control-Allow-Origin: *
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Transfer-Encoding: chunked
Content-Type: application/xml
[…XML Data…]
In response, the server returns a Access-Control-Allow-Origin header with Access-Control-Allow-Origin: *, which means that the resource can be accessed by any origin.
This pattern of the Origin and Access-Control-Allow-Origin headers is the simplest use of the access control protocol. If the resource owners at https://bar.other wished to restrict access to the resource to requests only from https://foo.example, (i.e no domain other than https://foo.example can access the resource in a cross-origin manner) they would send:
Access-Control-Allow-Origin: https://foo.example
CORS effect on Cookies
The most interesting capability exposed by both XMLHttpRequest and CORS is the ability to make "credentialed" requests that are aware of Cookies and HTTP Authentication information. By default, in cross-origin XMLHttpRequest invocations, browsers will not send credentials (i.e., cookies). A specific flag has to be set on the XMLHttpRequest object when it is invoked.
Consider the following example:
const invocation = new XMLHttpRequest();
const url = 'https://bar.other/resources/credentialed-content/';
function callOtherDomain() {
if (invocation) {
invocation.open('GET', url, true);
invocation.withCredentials = true;
invocation.onreadystatechange = handler;
invocation.send();
}
}
If we want to send Cookies to the server then withCredentials = true needs to set on the XMLHttpRequest instance. And if the server responds with some cookie, then the server also needs to include Access-Control-Allow-Credentials: true header along with Access-Control-Allow-Origin not being a wildcard (i.e., it shouldn't be "*"). Only then, the response and the response cookies will be made available to the JavaScript code. Otherwise, a CORS error will be printed on the devtools console.
The following example explains it:

Here is a sample exchange between client and server:
GET /resources/credentialed-content/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Connection: keep-alive
Referer: https://foo.example/examples/credential.html
Origin: https://foo.example
Cookie: pageAccess=2
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:34:52 GMT
Server: Apache/2
Access-Control-Allow-Origin: https://foo.example
Access-Control-Allow-Credentials: true
Cache-Control: no-cache
Pragma: no-cache
Set-Cookie: pageAccess=3; expires=Wed, 31-Dec-2008 01:34:53 GMT
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 106
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
[text/plain payload]
Although line 10 contains the Cookie destined for the content on https://bar.other, if bar.other did not respond with an Access-Control-Allow-Credentials: true (line 16), the response would be ignored and not be made available to the web content. Also notice the following: Access-Control-Allow-Origin: https://foo.example. If it was Access-Control-Allow-Origin: *, then browser would have not allowed the JavaScript to access the response or the response cookies as explained earlier.